
















.gif)










Если вы планируете сделку с его участием, мы настоятельно рекомендуем вам не совершать ее до окончания блокировки. Если пользователь уже обманул вас каким-либо образом, пожалуйста, пишите в арбитраж, чтобы мы могли решить проблему как можно скорее.
Ты, возможно, уже сталкивался с идентификацией по голосу. Она используется в банках для идентификации по телефону, для подтверждения личности на пунктах контроля и в бытовых голосовых ассистентах, которые могут узнавать хозяина. Знаешь ли ты, как это работает? Я решил разобраться в подробностях и сделать свою реализацию.
Характеристики голоса
В первую очередь голос определяется его высотой. Высота — это основная частота звука, вокруг которой строятся все движения голосовых связок. Эту частоту легко почувствовать на слух: у кого-то голос выше, звонче, а у кого-то ниже, басовитее.
Другой важный параметр голоса — это его сила, количество энергии, которую человек вкладывает в произношение. От силы голоса зависит его громкость, насыщенность.
Еще одна характеристика — то, как голос переходит от одного звука к другому. Этот параметр наиболее сложный для понимания и для восприятия на слух, хотя и самый точный — как и отпечаток пальца.
Предобработка звука
Человеческий голос — это не одинокая волна, это сумма множества отдельных частот, создаваемых голосовыми связками, а также их
Нам на помощь придет
Но преобразование Фурье — математическая функция, которая нацелена на идеальный, неменяющийся звуковой сигнал, поэтому она требует практической адаптации. Так что, вместо того чтобы выделять частоты из всей записи сразу, эту запись мы поделим на небольшие отрезки, в течение которых звук не будет меняться. И применим преобразование к каждому из кусочков.
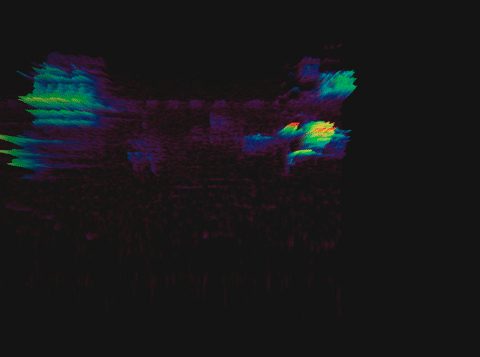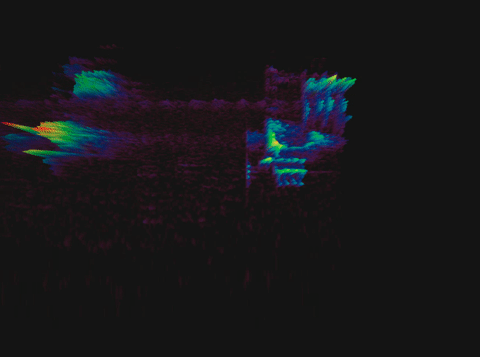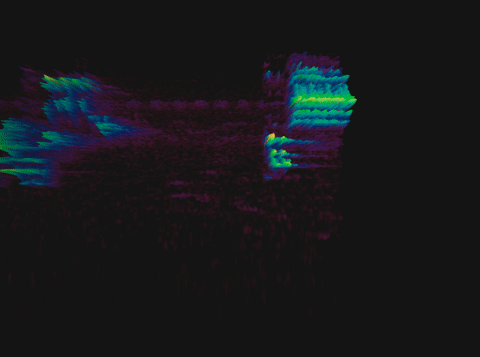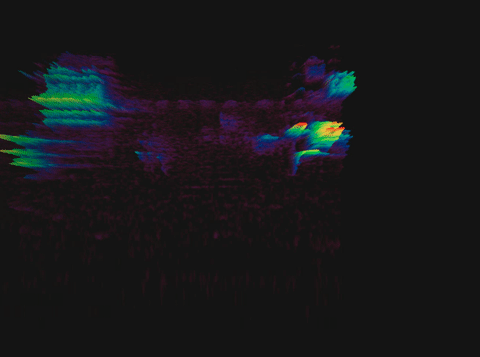
Спектрограмма пения птицы
Давай посмотрим, как выглядит спектр монотонного звука. Начнем с волны — синусоиды, которую издает, например, проводной телефон при наборе номера.

Видно, что, кроме основного пика, на самом деле представляющего сигнал, есть меньшие пики, гармоники, которые полезной информации не несут. Именно поэтому, прежде чем получать спектрограмму второго порядка, первую спектрограмму логарифмируют, чем получают пики схожего размера.

Логарифм спектрограммы синуса
Теперь, если мы будем искать спектрограмму второго порядка, или, как она была названа, «кепстр» (анаграмма слова «спектр»), мы получим во много раз более приличную картинку, которая полностью, одним пиком, отображает нашу изначальную монотонную волну.

Кепстр
Одна из самых полезных особенностей нашего слуха — его нелинейная природа по отношению к восприятию частот. Путем долгих экспериментов ученые выяснили, что эту закономерность можно не только легко вывести, но и легко использовать.

Зависимость мела от герца
Эту новую величину назвали

График перевода герца в мелы
Теперь попробуем применить все это на практике.
Идентификация с использованием MFCC
Мы можем взять длительную запись голоса человека, посчитать кепстр для каждого маленького участка и получить уникальный отпечаток голоса в каждый момент времени. Но этот отпечаток слишком большой для хранения и анализа — он зависит от выбранной длины блока и может доходить до двух тысяч чисел на каждые 100 мс. Поэтому из такого многообразия необходимо извлечь определенное количество признаков. С этим нам поможет мел-шкала.
Мы можем выбрать определенные «участки слышимости», на которых просуммируем все сигналы, причем количество этих участков равно количеству необходимых признаков, а длины и границы участков зависят от мел-шкалы.

Вычисление мел-частотных кепстральных коэффициентов
Вот мы и познакомились с мел-частотными кепстральными коэффициентами (MFCC). Количество признаков может быть произвольным, но чаще всего варьируется от 20 до 40.
Эти коэффициенты отлично отражают каждый «частотный блок» голоса в каждый момент времени, а значит, если обобщить время, просуммировав коэффициенты всех блоков, мы сможем получить голосовой отпечаток человека.
Тестирование метода
Давай скачаем несколько записей видео с YouTube, из которых извлечем голос для наших экспериментов. Нам нужен чистый звук без шумов. Я выбрал канал
Скачаем несколько видеозаписей любым удобным способом, например с помощью утилиты
Затем преобразуем видео в аудио, создаем несколько кусков разной длины без музыки или аплодисментов.
$ ffmpeg -ss 00:00:27.0 -i man1.webm -t 200 -vn man1.1.wav
Теперь разберемся с программой на Python 3. Нам понадобятся библиотеки numpy для вычислений и librosa для обработки звука, которые можно установить с помощью pip. Для твоего удобства все сложные вычисления коэффициентов упаковали в одну функцию librosa.feature.mfcc. Загрузим звуковую дорожку и извлечем характеристики голоса.

Результат:
same 0.08918786797751492
same 0.04016324022920391
diff 0.8353932676024817
diff 0.5290006939899561
diff 0.5996234966734799
diff 0.9143384850090941

Протестируем новую программу.
same 0.07287868313339689
same 0.07599075249316399
diff 1.1107063027198296
diff 0.9556985491806391
diff 0.9212706723328299
diff 1.019240307344966
Мы посчитали значения различных признаков.

Эти графики показывают, как наша программа сравнивает значения разных признаков. Красным и зеленым цветами обозначены коэффициенты, которые были получены из голосов двух женщин: по две записи на каждую. Линии одинакового цвета находятся близко друг к другу — голос одного и того же человека. Линии разных цветов расположены дальше друг от друга, поскольку это голоса разных людей.
Теперь сравним мужской и женский голоса.
same 0.07287868313339689
same 0.1312549383658766
diff 1.4336642787341562
diff 1.5398833283440216
diff 1.9443562070029585
diff 1.6660100959317368

Графики коэффициентов для мужчины и женщины
Здесь различия более выражены, это видно и на графике. Голос мужчины более низкий: пики больше в начале графика и меньше в конце.
Этот алгоритм действительно работает, и работает хорошо. Главный его недостаток — зависимость точности результата от шумов и длительности записи. Если запись короче десяти секунд, точность стремительно убывает.
Идентификация голоса с помощью нейронных сетей
Мы можем улучшить наш алгоритм с помощью нейронных сетей, которые на таких задачах показывают невероятную эффективность. Используем библиотеку


В этой модели используется два слоя долгой краткосрочной памяти (Long Short-Term Memory), которые позволяют нейронной сети анализировать не только сам голос, его высоту и силу, но и его динамические параметры, например переходы между звуками голоса.
Тестирование метода
Давай обучим модель и посмотрим на ее результаты.
Epoch 1/20
5177/5177 [====================] - loss: 0.4099 - acc: 0.8134 - val_loss: 0.2545 - val_acc: 0.8973
...
Epoch 20/20
5177/5177 [====================] - loss: 0.0360 - acc: 0.9944 - val_loss: 0.2077 - val_acc: 0.9807
[0.18412712604838924, 0.9819283065512979]
Отлично! 98% точности — хороший результат. Посмотрим статистику точности по каждому отдельному человеку.
woman1: 98.4%
woman2: 99.0% - цель
man1: 98.4%
Нейронная сеть справляется прекрасно, преодолевая большинство помех: шумы и ограничения по длине записи (нейронная сеть анализирует всего по одной секунде записи за раз). Такой способ идентификации человека наиболее перспективен и эффективен.
Выводы
Технологии распознавания человека по его голосу находятся только лишь на стадии научных исследований и разработок, и поэтому в открытом доступе хороших и популярных решений нет. Однако в коммерческом секторе такие программные продукты уже распространяются, чем облегчают работу сотрудников кол-центров, разработчиков умных домов. Теперь и ты можешь использовать этот прием на работе или для своих проектов.
Характеристики голоса
В первую очередь голос определяется его высотой. Высота — это основная частота звука, вокруг которой строятся все движения голосовых связок. Эту частоту легко почувствовать на слух: у кого-то голос выше, звонче, а у кого-то ниже, басовитее.
Другой важный параметр голоса — это его сила, количество энергии, которую человек вкладывает в произношение. От силы голоса зависит его громкость, насыщенность.
Еще одна характеристика — то, как голос переходит от одного звука к другому. Этот параметр наиболее сложный для понимания и для восприятия на слух, хотя и самый точный — как и отпечаток пальца.
Предобработка звука
Человеческий голос — это не одинокая волна, это сумма множества отдельных частот, создаваемых голосовыми связками, а также их
Для просмотра ссылки необходимо нажать
Вход или Регистрация
. Из-за этого в обработке сырых данных волны тяжело найти закономерности голоса.Нам на помощь придет
Для просмотра ссылки необходимо нажать
Вход или Регистрация
— математический способ описать одну сложную звуковую волну спектрограммой, то есть набором множества частот и амплитуд. Эта спектрограмма содержит всю ключевую информацию о звуке: так мы узнаем, какие в исходном голосе содержатся частоты.Но преобразование Фурье — математическая функция, которая нацелена на идеальный, неменяющийся звуковой сигнал, поэтому она требует практической адаптации. Так что, вместо того чтобы выделять частоты из всей записи сразу, эту запись мы поделим на небольшие отрезки, в течение которых звук не будет меняться. И применим преобразование к каждому из кусочков.
Спектрограмма пения птицы
Следующий шаг — посчитать спектрограмму второго порядка, то есть спектрограмму от спектрограммы. Это нужно сделать, поскольку спектрограмма, помимо основных частот, также содержит гармоники, которые не очень удобны для анализа: они дублируют информацию. Расположены эти гармоники на равном друг от друга расстоянии, единственное их различие — уменьшение амплитуды.Выбрать длительность блока несложно: в среднем один слог человек произносит за 70–80 мс, а интонационно выделенный вдвое дольше — 100–150 мс. Подробнее об этом можно почитать вДля просмотра ссылки необходимо нажать Вход или Регистрация.
Давай посмотрим, как выглядит спектр монотонного звука. Начнем с волны — синусоиды, которую издает, например, проводной телефон при наборе номера.
Видно, что, кроме основного пика, на самом деле представляющего сигнал, есть меньшие пики, гармоники, которые полезной информации не несут. Именно поэтому, прежде чем получать спектрограмму второго порядка, первую спектрограмму логарифмируют, чем получают пики схожего размера.
Логарифм спектрограммы синуса
Теперь, если мы будем искать спектрограмму второго порядка, или, как она была названа, «кепстр» (анаграмма слова «спектр»), мы получим во много раз более приличную картинку, которая полностью, одним пиком, отображает нашу изначальную монотонную волну.
Кепстр
Одна из самых полезных особенностей нашего слуха — его нелинейная природа по отношению к восприятию частот. Путем долгих экспериментов ученые выяснили, что эту закономерность можно не только легко вывести, но и легко использовать.
Зависимость мела от герца
Эту новую величину назвали
Для просмотра ссылки необходимо нажать
Вход или Регистрация
, и она отлично отражает способность человека распознавать разные частоты — чем выше частота звука, тем сложнее ее различить.
График перевода герца в мелы
Теперь попробуем применить все это на практике.
Идентификация с использованием MFCC
Мы можем взять длительную запись голоса человека, посчитать кепстр для каждого маленького участка и получить уникальный отпечаток голоса в каждый момент времени. Но этот отпечаток слишком большой для хранения и анализа — он зависит от выбранной длины блока и может доходить до двух тысяч чисел на каждые 100 мс. Поэтому из такого многообразия необходимо извлечь определенное количество признаков. С этим нам поможет мел-шкала.
Мы можем выбрать определенные «участки слышимости», на которых просуммируем все сигналы, причем количество этих участков равно количеству необходимых признаков, а длины и границы участков зависят от мел-шкалы.
Вычисление мел-частотных кепстральных коэффициентов
Вот мы и познакомились с мел-частотными кепстральными коэффициентами (MFCC). Количество признаков может быть произвольным, но чаще всего варьируется от 20 до 40.
Эти коэффициенты отлично отражают каждый «частотный блок» голоса в каждый момент времени, а значит, если обобщить время, просуммировав коэффициенты всех блоков, мы сможем получить голосовой отпечаток человека.
Тестирование метода
Давай скачаем несколько записей видео с YouTube, из которых извлечем голос для наших экспериментов. Нам нужен чистый звук без шумов. Я выбрал канал
Для просмотра ссылки необходимо нажать
Вход или Регистрация
.Скачаем несколько видеозаписей любым удобным способом, например с помощью утилиты
Для просмотра ссылки необходимо нажать
Вход или Регистрация
. Она доступна через pip или через официальный репозиторий Ubuntu или Debian. Я скачал три видеозаписи выступлений: двух женщин и одного мужчины.Затем преобразуем видео в аудио, создаем несколько кусков разной длины без музыки или аплодисментов.
$ ffmpeg -ss 00:00:27.0 -i man1.webm -t 200 -vn man1.1.wav
Теперь разберемся с программой на Python 3. Нам понадобятся библиотеки numpy для вычислений и librosa для обработки звука, которые можно установить с помощью pip. Для твоего удобства все сложные вычисления коэффициентов упаковали в одну функцию librosa.feature.mfcc. Загрузим звуковую дорожку и извлечем характеристики голоса.
Результат:
same 0.08918786797751492
same 0.04016324022920391
diff 0.8353932676024817
diff 0.5290006939899561
diff 0.5996234966734799
diff 0.9143384850090941
Протестируем новую программу.
same 0.07287868313339689
same 0.07599075249316399
diff 1.1107063027198296
diff 0.9556985491806391
diff 0.9212706723328299
diff 1.019240307344966
Мы посчитали значения различных признаков.
Эти графики показывают, как наша программа сравнивает значения разных признаков. Красным и зеленым цветами обозначены коэффициенты, которые были получены из голосов двух женщин: по две записи на каждую. Линии одинакового цвета находятся близко друг к другу — голос одного и того же человека. Линии разных цветов расположены дальше друг от друга, поскольку это голоса разных людей.
Теперь сравним мужской и женский голоса.
same 0.07287868313339689
same 0.1312549383658766
diff 1.4336642787341562
diff 1.5398833283440216
diff 1.9443562070029585
diff 1.6660100959317368
Графики коэффициентов для мужчины и женщины
Здесь различия более выражены, это видно и на графике. Голос мужчины более низкий: пики больше в начале графика и меньше в конце.
Этот алгоритм действительно работает, и работает хорошо. Главный его недостаток — зависимость точности результата от шумов и длительности записи. Если запись короче десяти секунд, точность стремительно убывает.
Идентификация голоса с помощью нейронных сетей
Мы можем улучшить наш алгоритм с помощью нейронных сетей, которые на таких задачах показывают невероятную эффективность. Используем библиотеку
Для просмотра ссылки необходимо нажать
Вход или Регистрация
для создания модели нейронной сети.
В этой модели используется два слоя долгой краткосрочной памяти (Long Short-Term Memory), которые позволяют нейронной сети анализировать не только сам голос, его высоту и силу, но и его динамические параметры, например переходы между звуками голоса.
Тестирование метода
Давай обучим модель и посмотрим на ее результаты.
Epoch 1/20
5177/5177 [====================] - loss: 0.4099 - acc: 0.8134 - val_loss: 0.2545 - val_acc: 0.8973
...
Epoch 20/20
5177/5177 [====================] - loss: 0.0360 - acc: 0.9944 - val_loss: 0.2077 - val_acc: 0.9807
[0.18412712604838924, 0.9819283065512979]
Отлично! 98% точности — хороший результат. Посмотрим статистику точности по каждому отдельному человеку.
woman1: 98.4%
woman2: 99.0% - цель
man1: 98.4%
Нейронная сеть справляется прекрасно, преодолевая большинство помех: шумы и ограничения по длине записи (нейронная сеть анализирует всего по одной секунде записи за раз). Такой способ идентификации человека наиболее перспективен и эффективен.
Выводы
Технологии распознавания человека по его голосу находятся только лишь на стадии научных исследований и разработок, и поэтому в открытом доступе хороших и популярных решений нет. Однако в коммерческом секторе такие программные продукты уже распространяются, чем облегчают работу сотрудников кол-центров, разработчиков умных домов. Теперь и ты можешь использовать этот прием на работе или для своих проектов.



